
*本文转载自知乎作者:殷玮
上次也聊到了,讨论自动驾驶芯片的意义并非单纯理解芯片原理,更需要理解计算并非是一个软件工作而是一个软硬件配合的工作。很多算法在不同的芯片上都可以实施,但是量产过程中需要在灵活性以及成本功耗之间做出权衡。而如果要做到这点,你必须理解芯片。
芯片的概念结构
当下芯片结构是复杂的,但简单划分就三种概念结构。冯。诺依曼结构,哈弗结构和改进哈弗结构。了解一个芯片的结构核心是看它的总线布置和存储器设计。
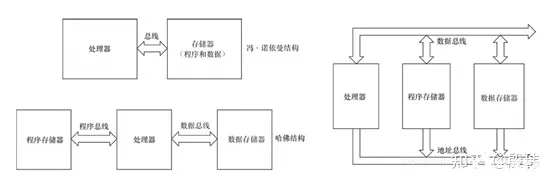
打个比方,假如芯片是一个「银行」,这个银行很小就两个人。一个负责拨算盘(计算),其他它都不管。一个负责记录文档(存储),把 「算什么?」(数据)和「咋么算?」(程序)都完整的用文档记录下来,方便和拨算盘的人沟通。他们之间定义了一个沟通方式(一组总线),内容包括了「文档从哪里取?放回哪里?」(寻址总线)和「文档具体内容是什么?」(数据总线)两大部分,换句话说,一组总线包括一个地址总线和一个数据总线。特别注意这里的总线上的「数据」对应着一份文档,不要和文档里「算什么?」的这个数据概念混淆了。
客户把原始的需求文档(包含输入数据和程序)交给负责记录的人后,根据定义的沟通方式,和负责实际计算的人一起反复来回的传递文档(拿程序指令,拿数据,返结果),最后把最终的计算结果通过记录的人反馈给客户。上面这种分工思路就是冯。诺依曼结构的核心,关键的特点就是客户只用和一个记录人员沟通就行,再复杂的需求都可以一股脑的给一个人,剩下的都是他们之间的事。整个过程非常灵活,这也是冯。诺依曼结构的最大优势。这种结构下程序指令存储地址和数据存储地址指向同一存储器的不同物理位置,因此程序指令和数据的宽度相同。但这种方式效率不高,因为记录的人每个时刻只能干一件事,要么告诉拨算盘的人咋么算,要么告诉它算什么。因此出现了哈佛结构,将程序指令和数据分开存储,指令和数据可以有不同的数据宽度。采用了独立的一组程序总线和一组数据总线。这就相当于原来 2 个人,现在三个人,记录员分了个工,一个就负责记录传递计算方法(程序),一个人就负责记录传递计算内容(数据)。两个人和拨算盘的人点对点沟通,但相互之间老死不往来。这种并行化自然提高了效率,原来要至少两个周期做完的事,一个周期就搞定了。可这种方法让客户要同时对应 2 个毫无联系的记录员这非常不友好。且如果需求侧重点不同,两个人的工作量常常不均衡导致浪费,如果由一个人担当(冯。诺依曼结构),这些问题都不存在。
为了解决这个平衡问题出现了改进哈弗结构。它只有一组总线供程序存储器和数据存储器分时共用。原来的哈佛结构需要4条(2 组)总线,改进后需要两条(1 组)总线,且保留了两个独立并行的存储器。也就是说,记录员还是为了效率做了分工,但沟通方式升级,走上了「敏捷之路」。不再是两两沟通的老国企做派,把客户和拨算盘的人也加入进来做了个四方沟通会(分时公用),归口统一保证了灵活性,同时分时也对并行化影响不大。
讨论完基本的结构思想这里有几点要着重提醒下。实际的芯片设计是对这几种概念结构的扩展和嵌套,比如 CPU 处理器虽然外部总线上看是诺依曼结构,但是由于内部高速缓存的二级设计,实际上对内已经算是改进哈佛结构了。
芯片的派系划分
接着我们聊下芯片的分类,梳理分类首先要区分芯片的两个大类通用芯片(CPU, GPU, DSP 等)和定制芯片(FPGA, ASIC 等),这个大类划分很重要,两者有本质上的不同。同样用银行做比喻,通用芯片就是 「银行柜员」 而定制芯片就是 「ATM 机」。
通用芯片关键是「通用」 二字,这意味着其必须具备处理各式各样千奇百怪的指令要求,并且经常同时存在多个外部设备的请求,它必须拥有随时中止目前的运算转而进行其他运算,完成后再从中断点继续当前运算的能力。就好比银行柜员,客户要办的业务千奇百怪,时常还来个缺德的插队骂娘或者站着位置不走撩你两下的人存在。柜员都要应对。而为了做到这一点通用芯片有复杂的控制取指译码流程,Cache 内存分级机制(缓和高速 CPU 与低速内存的临时指令存储器),真正的计算单元 ALU 只占了通用芯片不大的一部分,更多设计是为了灵活性存在的,在计算效率和通用性上的权衡上牺牲前者选择后者。
计算机元件无法理解我们的指令,它们只能理解晶体管实现的两种状态:「开」 和 「关」 的含义,对应的就是 1 和 0 这,为了让指令变成 CPU 能理解的 0 和 1,CPU 需要一个专门的译码器来翻译我们的指令。这个过程分为两步:「取指」(从一个专门存放指令的存储器中将需要执行的指令提取出来)和 「译码」(根据特定的规则将指令翻译成计算单元能够理解的数据)。
当我们在上文讨论芯片结构的时候更多的是在讨论通用芯片的结构,是在讨论说满足客户变化需求的时候,哪种「人员组织形式和沟通方式」是最高效的。
而定制芯片就是完全的另一个概念,虽然它也有结构思想在里面,但是就像你不会去讨论一个程序的「人员组织架构」一样,在这种芯片里根本就没有时序中断,取指译码这些为了灵活性而设计的概念。相比通用芯片,定制芯片是没有 「人性」 的,就是一个 ATM 机,其给客户定义了清晰的操作流程,省去了中断等大量灵活性设计,撩小姐姐的一套对机器人是不成立。
打个比方,比如一个比大小的逻辑用冯诺依曼结构的 CPU 至少需要几条指令完成,但用 FPGA 就根本不用考虑时序周期,只要串联几个逻辑单元,在一个周期就搞定了。但如果再增加几个逻辑,CPU 还是在相同逻辑资源下用几个指令完成,但是 FPGA 就需要额外占用另一部分逻辑资源完成计算。再比如 FPGA 和 GPU(GPU 是通用芯片)在并行化上有类似的思想,但两者实际没有多少可比性,你不会把三个柜员的办理通道和 ATM 机理存在在三个恰好并行的流程做比较一样。还有人在信号处理效率上把 DSP 和 FPGA 拿出来对比,我觉得这些零零种种的比较都没有太大意义。为灵活性存在的 「人」(通用芯片),和为效率存在的 「机器」(定制芯片)是两个维度的事情,不要从性能上去强行比较。
从这里我们可以大致看出来,两者的几个重要差异。定制芯片是对已经固化的业务进行降本增效,就像银行用 ATM 机,代替成本更高的柜员处理一些常规银行业务。而通用芯片是为了对一些无法或者暂时没有固化的业务作出的灵活设计。两者没有优劣之分。
了解了芯片的两个大方向,我们看下这两个大方向内部的细分差异以及联系。通用芯片下的 CPU(MPU), GPU, DSP,MCU 之间同样存在细分差异。
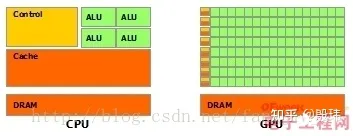
CPU 和 MPU 可以简单理解为一个概念,只是理解范畴上的区别。CPU 和 GPU 之间的区别更多的是核的数量。CPU 虽然有多核,但基本不超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并有更复杂的逻辑判断硬件,就像银行里常备的 3-4 个柜台的柜员,擅长处理客户很复杂的业务。而 GPU 的核数远超 CPU 每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单,更像是 500 多个电话客服柜员,处理一些相对简单但数量众多的客户业务。
DSP(数字信号处理芯片)是一类特殊的 CPU,采用了上面说的哈佛结构,且存在专用的硬件算法电路和专门的寻址模式。它具有通用芯片设计的灵活性,但在实时运算过程中很少变化,因此特化了业务流程的性能(记录和计算过程)。就像是某个办理 “外汇存取” 的专业柜台会部署一些特化的柜员和流程。DSP 对于专用信号(视频编解码,通讯信号)的处理能力远远的优于一般 CPU。当然普通柜台也可以处理展业柜台的业务,但性价比就很差了,如果需求很多开设专门的柜台就变得有意义,这些还是和客户需求有关。用 DSP 处理专门的信号流常具有执行时间可控,芯片性价比高等优点。
讲完了通用芯片,定制芯片也有两个主要方向,FPGA 和 ASIC。两者核心的区别就是固化程度。FPGA 仍然具有一定的灵活性(但远逊于通用芯片),而 ASIC 则是完成固化的设计(也存在和 FPGA 类似的部分编辑的产品存在)。类似可以编程的 ATM 机和完全固化的 ATM 机,两者区别最大的维度还是成本和功耗。
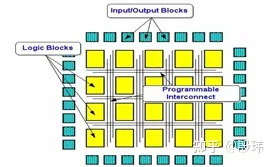
FPGA 最早是从专用集成电路发展而来的半定制化的可编程电路,是高端的 CPLD (Complex Programmable Logic Device 复杂可编程逻辑器件)。FPGA 可以实现一个 DSP, GPU 甚至是 CPU 的功能,就像之前说的把柜员业务固化为 ATM 机操作流程一样。但不是说 FPGA 可以代替 CPU,这是设计目的上的大方向差异,反复强调。
FPGA 是一堆逻辑门,通过硬件描述语言 HDL 把它转成电路连接,从最基本的逻辑门层面上连接成电路。虽然看起来像一块 CPU,其实是完全硬件实现的。 根据一个固定的模式来处理输入的数据然后输出。FPGA 片上大部分都是计算单元,没有控制单元并不代表 FPGA 不会执行指令,事实上 FPGA 里控制单元的角色由单元和单元之间可编程逻辑连接线来完成的,通过 HDL 编程更改每个单元的运算逻辑和单元之间的连接方式,从而使其达到和一般的运行程序差不多的效果。由于省去了 CPU 的取指和译码两个步骤,FPGA 重复运行相同代码的效率得到了极大的提高,也因此,其无法应对没有被编程过的指令。
ASIC 就是专用 IC,没有明确的定义。可以理解为除了单片机、DSP、FPGA 之类的能叫出名的 IC,剩下的都是 ASIC。ASIC 原本就是专门为某一项功能开发的专用集成芯片。后来 ASIC 发展了一些,称为半定制专用集成电路,相对来说更接近 FPGA,甚至在某些地方,ASIC 是个大概念,FPGA 属于 ASIC 的一部分,也常常被作为 ASIC 开发的预研。其代表了在需求一定的情况下,对性价比的极致追求。
芯片之上的集成
在上面我偷偷遗漏了一个概念 MCU,原因是其本身不是一种芯片类型而是一种集成方式,SOC 芯片也是同样的道理,两者的区别是程度上的不同。在自动驾驶汽车领域 MCU 更多的是集成了更多的输入和输出设备在芯片当中,方便更好的控制,因此叫做微控制器而不是微处理器。而 SOC 是在更高的层面上将不同的芯片做了进一步的集成,维度更高。如果 MCU 是一种人员组织最终形成一个公司对外服务,那 SOC 更像是公司级别的组织形成了一个行业对外服务。
单片机是 MCU 的通俗说法,经典的 51 系列就是一堆 IO 口,后来慢慢的把常用的 PWM, AD 之类的功能加入了单片机之中。其构成等价于一个带了更多外设 CPU,但侧重点是讨论其外设的部分。在 PWM,AD 等之上继续发展其外设也就形成了汽车行业熟悉的 ECU 即电子控制单元,同时泛指汽车上所有电子控制系统,可以是转向 ECU,空调 ECU 等。
ECU 一般由 MCU,扩展内存,扩展输入和输出(CAN / LIN,AD,PWM 等),电源电路和其他一些电子元器件组成,特定功能的 ECU 还带有诸如红外线收发器、脉冲发生器,强弱电隔离等元器件。整块电路板设计安装与一个铝质盒内,通过卡扣或者螺钉方便安装于车身钣金上。
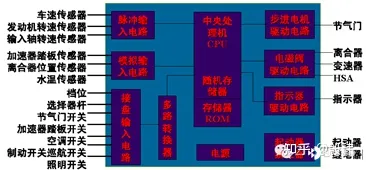
在输入处理电路中,ECU 的输入信号主要有三种形式,模拟信号、数字信号 (包括开关信号)、脉冲信号。模拟信号通过 A / D 转换为数字信号提供给微处理器。
在输出电路中,微处理器输出的信号往往用作控制电磁阀、指示灯、步进电机等执行件。微处理器输出信号功率小,使用 + 5 v 的电压,汽车上执行机构的电源大多数是蓄电池,需要将微处理器的控制信号通过输出处理电路处理后 (D / A, 放大等) 再驱动执行机构。
电源电路中,传统车的 ECU 一般带有电池和内置电源电路,以保证微处理器及其接口电路工作在 + 5 v 的电压下。即使蓄电池电压有较大波动时,也能提供稳定电压保证系统的正常工作。
一般搭载 8 位 MCU 的 ECU 主要应用于风扇控制、空调控制、雨刷、天窗、门控等较低阶的控制功能。16 位 MCU 主要应用如引擎控制、齿轮与离合器控制等。32 位 MCU 应用于多媒体信息系统,实时性的安全动力系统以及复杂的 X - by - wire 等传动功能。更复杂的功能就不在 MCU 或者 ECU 的讨论范围内了。
随着自动驾驶的发展,ECU 的概念进一步升级,更为流行的说法是域控制器,其无外乎就是把 MCU 变成了 SoC(片上系统),同时集成了更多的外围设备而已。目前域控制器搭载的主流通用芯片(GPP)多采用 SoC 的芯片设计方法,通过 HDL 语言在 SoC 内由电路集成各种功能芯片。在 SoC 中各种组件(IP 核)采用类似搭积木的方法组合在一起。IP 核(诸如典型的 ARM 内核设计技术)被授权给数百家半导体厂商,做成不同的 SoC 芯片。还可能集成 GPU、编解码器(DSP)、GPS、WiFi 蓝牙基带等一系列功能。如果看一下高通或者 TI 的芯片,基本是一个 ARM 核控制整体运算,一个 DSP 处理语音编解码, 一个 GPU 负责图像运算,一个基带和天线处理模块负责通信,以及 GPS,安全加密等林林总总的特殊芯片。
过去极端情况下自动驾驶的原型处理器功耗可以高达 5000W,不仅昂贵且需要搭载额外的散热装置。SoC 和 ASIC 的发展给我们带来很多启示,回到我经常提及的贯穿整个自动驾驶系统的灵活性。在新的 SoC 世界里,你不会从不同的供应商那里组装物理元件。相反,你从不同的供应商那里组装 IP 从而获得更好的集成度,也因此更容易降低功耗和成本。
软硬件的匹配设计
大部分自动驾驶算法公司都想定制或自制 ASIC/SOC 计算平台,原因还有另一个层面来源于软硬件的匹配问题。算法的性能与硬件设计往往脱离不开。追求模块化就要牺牲利用率。要提高利用率就需要软硬件一体设计。你的算法是用 GPU 合适还是 CPU 合适,网络模型一次用多少内存又同时使用多少 MAC,由此来设计芯片。或者说反过来给定一个芯片,我的算法要如何兼容,是否要减少内存访问次数提高利用率,还是要迁移部分 CPU 基于规则的算法,改为用 GPU 基于深度学习来实现。软硬件一起考虑往往才能充分利用好系统性能。
不同的芯片,不同的算法和需求,往往有最优的组合方式。比如一个经典底层而常用的算法应用,需求是大量的且竞争是激烈的时候,ASIC 就是很好的选择。为了一个简单功能(比如编解码)支付一个 ARM 的授权是愚蠢的。
如果算法非常经典且底层,但仍然有改进的空间和需要适配的不同场景,信号流的处理(手机语音处理)可以直接使用 DSP,而更复杂的输入输出逻辑算法(比如图像 SIFT 特征处理),就可以交给 FPGA 来做,性能相对于 CPU 都可以由 30 - 100 倍的提升,且成本和耗能更小。
在复杂算法领域相对于 CPU,GPU 的众核架构把同样的指令流并行发送到众核上,采用不同的输入数据执行。所以 GPU 比 CPU 更适合并行算法,而串行的复杂规则逻辑则更适合 CPU 处理。更具体的说,如果标量视为零阶张量,矢量视为一阶张量,矩阵视为二阶张量。CPU 对应标量计算,主要是路径规划和决策类算法,常用的传感器融合如卡尔曼滤波算法也多是标量运算。GPU 则对应矢量或者说向量计算,包括点云,地图,深度学习,核心是矩阵运算。用 CPU 编写程序时,更适合通过精益化逻辑来提升性能。而用 GPU 编写程序时,则更合适利用算法并发处理来提升性能。
以上,对芯片的理解到这个程度一般工作就能够开展了。















